Introduction¶
DIVA is a framework for deploying video analytics in a multi-camera environment, funded by IARPA and licensed under BSD license.
From the DIVA Website:
The DIVA program seeks to develop robust automatic activity detection for a multi-camera streaming video environment. Activities will be enriched by person and object detection. DIVA will address activity detection for both forensic applications and for real-time alerting.
DIVA is being developed as an open source, end to end system for incorporating state of the art activity detection algorithms into multi-camera streaming video environments. These algorithms include both traditional and deep learning approaches for activity detection. Since almost all these algorithms are designed to work in offline single stream environment, porting them to online multi-stream environment requires significant effort on part of the researchers and developers. DIVA seeks to reduce this effort and streamline the process by providing an open standard for reasoning across multiple video streams obtained from geographically and topologically diverse environment.
The DIVA Framework is based on KWIVER an open source framework designed for building complex computer vision systems. Some of the features of the framework are:
A video processing pipeline architecture designed to support multi-threaded and distributed processing system designs.
A rich and growing collection of computer vision processing modules
A dynamic design which supports a wide range of third party libraries and frameworks including OpenCV, deep learning frameworks such as Caffe and Darknet as well as many other libraries helpful for developing complete computer vision systems. See KWIVER’s third party management repository Fletch for more details.
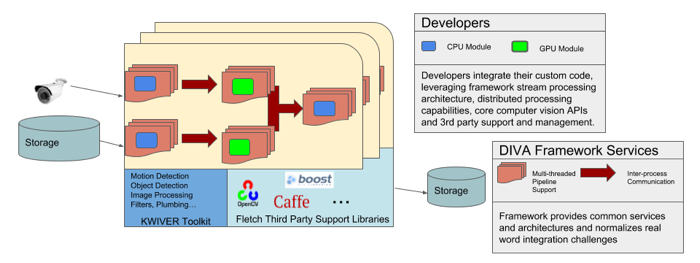
Developers use the framework by implementing new algrothim implementations, processes or core datatypes. These become plugins to the the framework and can then be combined with other framework modules to build out fully elaborated DIVA analytics systems.
The process of integrating a DIVA activity detector into the DIVA framework primarily consists of creating a plugin or collection of plugins chiefly be implementing a configuration and frame processing function and combining them with other provided processes (such as I/O processes) into sophisticated processing pipelines.
Features¶
As noted, the DIVA framework is based on KWIVER <http://www.kwiver.org>_, leveraging existing algorithms and infrastructure. The major features of KWIVER that are used by DIVA include
Abstract Algorithms: KWIVER separates the definition and implementation of standard algorithms. This allows the user to have multiple implementation of an algorithm that can be selected at runtime as a configuration parameter. The definition and implementations are extensible in c++ which allows user to integrate their algorithms at different levels of abstraction in the framework. Out of the box, KWIVER supports numerous algorithm definition and implementation that can be found in algorithms and arrows directory.
Data Types: Along with the standard types, KWIVER provides a set of complex data types designed for the computer vision algorithms, e.g. BoundingBox. These types provide a standard input/output interface for the algorithms to pass data. Thereby allowing users to chain algorithms and exchange data between them.
Multi-threaded reconfigurable pipelines: The chaining mechanism in KWIVER are called pipelines. A pipeline defines the relationship of the components of a system in text format or programmatically. The pipelines are agnostic to the language in which the process are written and can use any and all the processes that KWIVER and DIVA provides. By default pipelines are multi-threaded and can be paired with ZeroMQ to distribute the components of a pipeline across the network.
Interprocess communication: With deep networks becoming state of the art for almost all computer vision task, GPU footprint of the components of a large system is a major concern. For example, creating an instance of activity detector with `ACT`_ to localize activities and Faster RCNN to localize participants in the activity would require ~15Gb of GPU memory and would rely on multiple GPUs. To manage the communication between the algorithms and synchronizing the input/outputs, KWIVER uses ZeroMQ’s. This allows the user to distribute the components of their system to any networked system with the resource to run it.
Resources¶
DIVA Framework Github Repository This is the main DIVA Framework site, all development of the framework happens here.
DIVA Framework Issue Tracker Submit any bug reports or feature requests for the framework here.
DIVA Framework Main Documentation Page The source for the framework documentation is maintained in the Github repository using Sphinx A built version is maintained on ReadTheDocs. A good place to get started in the documentation, after reading the Introduction is the UseCase section which will walk you though a number of typical use cases with the framework.
KITWARE has implemented two “baseline” activity recognition algorithms in terms of the Framework: